Lab 2-2: Type II Error and Power#
What is the Type II error and Power for your test on the mean from Lab 2-1?
In this case, we will assume that true mean has increased by 30% (true mean is 1.3 times the early mean), and that the pooled standard deviation has increased by 10% (true pooled standard deviation is 1.1 times \(\sigma'\), where \(\sigma'\) is our test estimate of pooled estimator for the two observed data sets).
# import libraries we'll need
import pandas as pd
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
%matplotlib inline
# Read the excel file
skykomish_data_file = '../data/Skykomish_peak_flow_12134500_WY1929_2025.xlsx'
skykomish_data = pd.read_excel(skykomish_data_file)
# Preview our data
skykomish_data.head(3)
/opt/hostedtoolcache/Python/3.11.14/x64/lib/python3.11/site-packages/openpyxl/worksheet/_reader.py:329: UserWarning: Unknown extension is not supported and will be removed
warn(msg)
| date of peak | water year | peak value (cfs) | gage_ht (feet) | |
|---|---|---|---|---|
| 0 | 1928-10-09 | 1929 | 18800 | 10.55 |
| 1 | 1930-02-05 | 1930 | 15800 | 10.44 |
| 2 | 1931-01-28 | 1931 | 35100 | 14.08 |
# Divide the data into the early period (before 1977) and late period (after and including 1977).
skykomish_before = skykomish_data[ skykomish_data['water year'] < 1977 ]
skykomish_after = skykomish_data[ skykomish_data['water year'] >= 1977 ]
Calculate Type II error and Power#
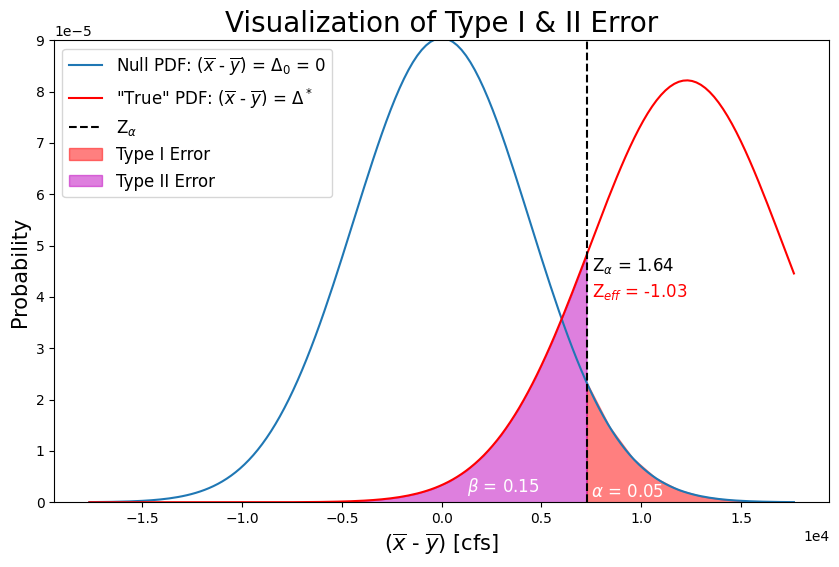
Recall from the class lectures that the Type II error, \(\beta\), is the probability that we would incorrectly conclude that a change in the probability distribution had NOT taken place, if in fact a change of a certain assumed magnitude had occurred (failure to reject a false null hypothesis).
Type II error is a function of both \(\alpha\) (expressed in the equation below with \(z_{\alpha}\)), and the posited true nature of the probability distribution we are hoping to detect (we get to decide how different the true probability distribution is from the null hypothesis, and then see how likely we would be to make a mistake).
\({ \beta = P\big((\overline{X}-\overline{Y}) < \Delta_0 + z_{\alpha}\sigma'\big)}\)
where \(\sigma'\) is the pooled standard deviation from \(\overline{X}\) (the later period) and \(\overline{Y}\) (the earlier period):
\(\sigma' = \displaystyle\sqrt{ \displaystyle\frac{s^2_X}{n_X} + \displaystyle\frac{s^2_Y}{n_Y} }\)
Power, \((1-\beta)\), is the probability that we would correctly conclude that a change in the probability distribution had taken place, given a certain assumed magnitude change had occurred.
If we assume a true normal distribution with mean \((\overline{X}-\overline{Y}) = \Delta^* = 0.3\cdot\overline{Y}\)
and a true standard deviation \(\sigma^* = 1.1\cdot\sigma'\)
then we need to solve for the intersection of \( \Delta^* + z_{eff}\sigma^* = \Delta_0 + z_{\alpha}\sigma'\)
# Get the length of our two datasets
nX = len(skykomish_after)
nY = len(skykomish_before)
# Set our alpha and confidence
alpha = 0.05
conf = 1 - alpha
# Calculate z_alpha from a normal distribution
z_alpha = stats.norm.ppf(conf)
# Get our means
meanX = skykomish_after['peak value (cfs)'].mean()
meanY = skykomish_before['peak value (cfs)'].mean()
# Get our standard deviations
sdX = skykomish_after['peak value (cfs)'].std(ddof=1)
sdY = skykomish_before['peak value (cfs)'].std(ddof=1)
# Calculate the pooled standard deivation
sigma_prime = np.sqrt(sdX**2/nX + sdY**2/nY)
# For our null hypothesis PDF
delta_0 = 0
# Set our expected change in the mean (30% of early period mean)
delta_star = .3 * meanY
# Set our expected change in the standard deviation (1.1 times the pooled standard deviation)
sigma_star = 1.1 * sigma_prime
# Rearranging the equation above to solve for the "z effective" value, the z value on our postulated "true" PDF
z_eff = ((delta_0 + z_alpha*sigma_prime) - delta_star) / sigma_star
# Look up the cdf value of the postulated true distribution at this point to get our beta vlaue
beta = stats.norm.cdf(z_eff)
print("Type II error: {}".format(np.round(beta,4)))
# Thus, our confidence that we are not commiting Type II error is
power = 1 - beta
print("Power: {}".format(np.round(power,4)))
Type II error: 0.1504
Power: 0.8496
Compute the two-sample z-test value:
\(ztest = \displaystyle\frac{(\bar{X}-\bar{Y})-\Delta_0}{\sigma'}\)
z_test = ((meanX - meanY) - delta_0) / sigma_prime
print("z-test = {}".format(np.round(z_test,2)))
p = 1 - stats.norm.cdf(z_test)
print("p = {}".format(np.round(p,4)))
z-test = 2.6
p = 0.0046
# Make a plot
plt.figure(figsize=(10,6))
# Create values for z
z = np.linspace(-4, 4, num=160) * sigma_prime
# Plot the Null PDF
plt.plot(z, stats.norm.pdf(z, delta_0, sigma_prime), label='Null PDF: ($\overline{x}$ - $\overline{y}$) = $\Delta_0$ = 0')
## Plot the postulated True PDF
plt.plot(z, stats.norm.pdf(z, delta_star, sigma_star), color='red', label=r'"True" PDF: ($\overline{x}$ - $\overline{y}$) = $\Delta^*$')
# Plot where z_alpha is
plt.axvline(z_alpha*sigma_prime, color='black', linestyle='--', label=r'Z$_\alpha$')
# Add labels here with z_alpha and z_eff values
plt.text(z_alpha*sigma_prime+300, 4e-5, r'Z$_{eff}$ = ' + str(round(z_eff,2)),fontsize=12, color='r')
plt.text(z_alpha*sigma_prime+300, 4.5e-5, r'Z$_{\alpha}$ = ' + str(round(z_alpha,2)),fontsize=12, color='k')
# Plot where z_test is
#plt.axvline(z_test*sigma_prime, color='k', linestyle=':', label=r'z-test')
# Add labels here with z_test
#plt.text(z_test*sigma_prime+300, 1e-5, r'z-test = ' + str(round(z_test,2)),fontsize=12, color='k')
# Shade in the Type I Error area
shade = np.linspace(z_alpha*sigma_prime, np.max(z), 10)
plt.fill_between(shade, stats.norm.pdf(shade, delta_0, sigma_prime) , color='red', alpha=0.5, label='Type I Error')
# Add label here with alpha value
plt.text(z_alpha*sigma_prime+200, 0.1e-5, r'$\alpha$ = ' + str(round(alpha,2)),fontsize=12, color='w')
# Shade in the Type II Error area
shade = np.linspace(np.min(z),z_alpha*sigma_prime, 30)
plt.fill_between(shade, stats.norm.pdf(shade, delta_star, sigma_star) , color='m', alpha=0.5, label='Type II Error')
# Add label here with Beta value
plt.text(z_alpha*sigma_prime-6000, 0.2e-5, r'$\beta$ = ' + str(round(beta,2)),fontsize=12, color='w')
# Add title, legend, and labels
plt.title('Visualization of Type I & II Error',fontsize=20)
plt.xlabel('($\overline{x}$ - $\overline{y}$) [cfs]', fontsize=15)
plt.ylabel('Probability',fontsize=15)
plt.ylim(0, 9e-5)
plt.ticklabel_format(axis='both', style='sci', scilimits=(0,0))
plt.legend(loc='upper left',fontsize=12);