Lab 1-4: Probability distributions and random numbers#
Creating and plotting random normal data#
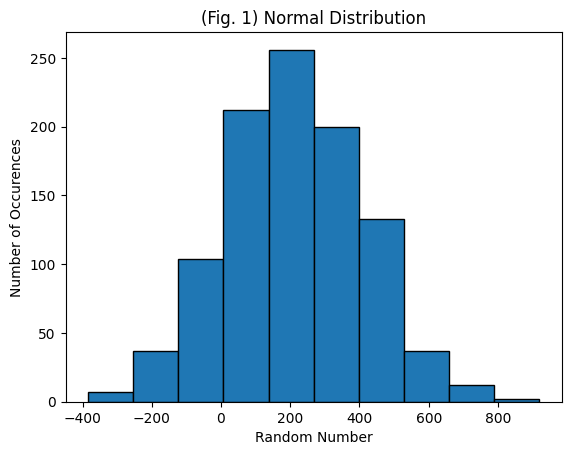
This section will introduce you to creating and plotting random normal data using the numpy and math modules. The random normal data set will have a mean of 100, standard deviation of 25, and sample size of 1000.
# First, import the libraries you will need
import numpy as np
import matplotlib.pyplot as plt
#Also, add code to make sure your plots appear in your Jupyter notebook
%matplotlib inline
# Create variables for the mean, standard deviation, and sample size of the data
# as well as a variable for the number of bins used to plot the data as a
# histogram later.
mean = 200
sd = 200
size = 1000
nbins = 10
# Create random data using the properties defined above and the np module.
data_normal = np.random.normal(mean, sd, size)
Now that the data has been created, plot the data as a histogram. Try changing the variables defined above, especially the number of bins and sample size, and seeing how the graph changes.
plt.figure()
plt.hist(data_normal, nbins, ec="black")
plt.title('(Fig. 1) Normal Distribution')
plt.xlabel('Random Number')
plt.ylabel('Number of Occurences')
Text(0, 0.5, 'Number of Occurences')
Creating Random Lognormal Data#
Next, generate and plot random lognormal data with the same mean, standard deviation, and sample size as above. Refer back to Lecture 2 in class or to wikipedia’s page on the lognormal distibution: https://en.wikipedia.org/wiki/Log-normal_distribution. Note that the parameters \(\mu\) and \(\sigma\) in the lognormal distribution refer to the mean and the standard deviation of the variables natural logarithm, not of the original dataset. If we use “mean” and “sd” to refer to what we would calculate for the original dataset, then we can calculate \(\mu\) and \(\sigma\) as follows:
First, the mean of \(ln(RandomData)\) is \({\mu} = ln\bigg(\frac{mean^2}{\sqrt{mean^2 + sd^2}}\bigg)\) and the standard deviation is \({\sigma} = \sqrt{ln\bigg(\frac{mean^2 + sd^2}{mean^2}\bigg)}\).
mean = 100
sd = 25
size = 1000
nbins = 20
# Find the mean and standard deviation for ln(RandomData)
mu = np.log(mean**2 / np.sqrt(mean**2 + sd**2))
sigma = np.sqrt(np.log((mean**2 + sd**2) / (mean**2)))
# Create random data
data_lognormal = np.random.lognormal(mu, sigma, size)
Now plot the data. Try changing the variables above to see how the graph changes.
plt.figure()
plt.hist(data_lognormal, nbins, ec="black")
plt.title('(Fig. 2) Lognormal Distribution')
plt.xlabel('Random Number')
plt.ylabel('Number of Occurences')
Text(0, 0.5, 'Number of Occurences')

Creating Random Uniform Data#
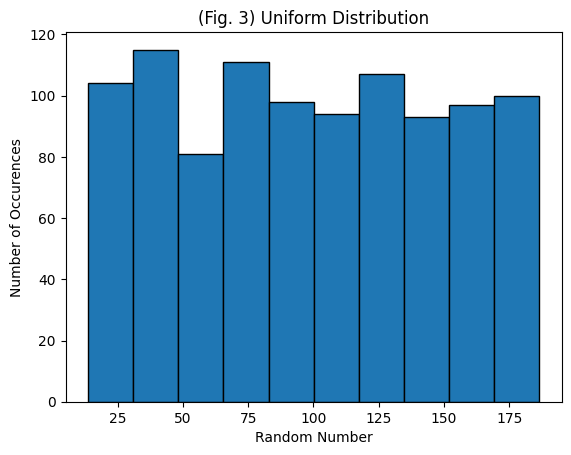
Next, generate random uniform data with the same mean, standard deviation, and sample size as above. Consider Lecture 2 on the uniform distribution or see wikipedia: https://en.wikipedia.org/wiki/Uniform_distribution_(continuous)
First, for \({f(x)} = \frac{1}{b-a}\), the mean is \({\mu} = \frac{b+a}{2}\) and the standard deviation is \({\sigma} = \frac{b-a}{\sqrt{12}}\).
So, \({a} = \mu-\sigma\sqrt{3}\) and \({b} = \mu+\sigma\sqrt{3}\).
mean = 100
sd = 50
size = 1000
nbins = 10
# Find the bounds for uniform data
a = mean - sd*np.sqrt(3)
b = mean + sd*np.sqrt(3)
# Create random data
data_uniform = np.random.uniform(a, b, size)
Now plot the data. Try changing the variables above to see how the graph changes.
plt.figure(3)
plt.hist(data_uniform, nbins, ec="black")
plt.title('(Fig. 3) Uniform Distribution')
plt.xlabel('Random Number')
plt.ylabel('Number of Occurences')
Text(0, 0.5, 'Number of Occurences')
Fun with fake data!#
One of the most reliable tests of any statistical method or technique is to try it out on data where you know the answer. This lets you see if the methodology gives you the result you expect. The best way to get data that truly understand is to make it up yourself.
Try the following activity:
Create data with known distributions, all with the same mean = 60, and standard deviation = 40
Generate 1000 random numbers with a normal distribution with
np.random.normal()Generate 1000 random numbers with a log-normal distribution with
np.random.lognormal()Generate 1000 random numbers with a uniform distribution with
np.random.uniform()(You’ll need to think about what the interval should be for this uniform distribution.)
For each set of random numbers, make the following plots:
histogram
boxplot
quantile plots
PDFs
Compare the plots, and discuss how you can tell the distributions apart.
Now repeat the above steps, but generate 100 random numbers for each set, then 25 numbers, then 10 numbers.
For each of these, can you tell the distributions apart?
What is the sample mean and standard deviation for each?
Discuss the difference between a sample population and the true population.